7.5 Making use of the tweets
Our community model makes good use of the labels being provided by our crowd workers. But there is some information that our model is not making use of: the tweets themselves. We do not expect to be able to build a model that could accurately label tweets – if we could do this, then we would not need the human crowd workers! However, we can build a model to label tweets somewhat accurately, although less accurately than a human worker. Such a model is useful because it can triage the tweets – in other words, work out if a tweet is likely to be about an emergency situation and, if so, send it to be labelled with high priority.
To predict the label for each tweet we can construct a classifier model. We could use the one from Chapter 4 but instead we will use an even simpler classifier based on the following assumption:
- The probability that a tweet contains a particular word depends only on the true label of the tweet.
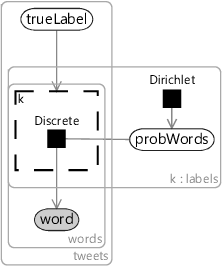
To model this assumption, we will need a variable to represent an observed word in a tweet. To represent a word, we assume that we have a vocabulary of all words that we want to represent. Then, a word in a tweet will be represented as an index into this vocabulary – 0 for the first word in the vocabulary, 1 for the second, and so on. We will use a variable called word to represent each word and put it inside a plate across the words in a tweet and also inside the existing tweets plate, since there are different words in each tweet.
We will also need a variable probWords to hold the probability of each word. Since we need a word probability for each possible true label, probWords needs to lie in a plate across the labels. Figure 7.20 shows the resulting model which includes these two variables and connects them to the trueLabel variable. This model is a kind of naive Bayes classifier since it assumes that the probability of each word does not depend on the presence or absence of other words in the tweet. This is not a particularly good assumption to make about words since certain words often occur together, such as in phrases. We will work with it for now and then discuss how it could be improved later.
An important question is: what data should we use to train this model? We could use the gold labels, but there are relatively few tweets with gold labels. Training our classifier only on tweets with gold labels would mean ignoring most of the tweets. But we would like to be able to train on all of the tweets!
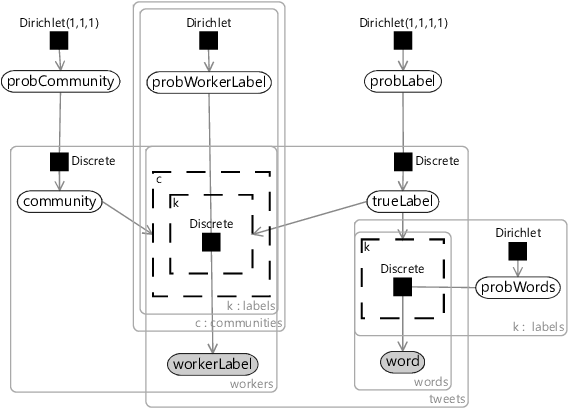
Our community model gives us inferred labels for all tweets, whether or not they have gold labels. If we could use this inferred label from this model, we could train our classifier on all of the tweets. To achieve this, we can embed the words model of Figure 7.20 inside our existing community model, and share the trueLabel variable between them – making one unified model. The resulting combined model is shown in Figure 7.21.
Results with words
Because our combined model can use inferred labels for training, we are able to train it on all 20,000 tweets in our training set. We use a vocabulary consisting of all words that occur at least 10 times in this training set, to ensure there is a reasonable amount of data for each word. To see how well our model works for triage, we then apply it to the validation set, but without supplying any worker labels. Unlike earlier models, this model can provide meaningful predictions without any worker labels, by making use of the words in each tweet. The resulting predictions have an accuracy of 66.5%. As expected, this is much lower than the accuracy of 92.5% we achieved when making use of worker labels. Nonetheless, it may still be useful for triaging tweets. To explore how useful it can be, let’s take a look at the confusion matrix, shown in Figure 7.22.
The confusion matrix shows that our accuracy differs for different types of tweet. For example, the accuracy at predicting the label of Negative tweets is much higher than for Neutral tweets. Suppose we wanted to detect Negative tweets urgently, as we would for emergency tweets in a crisis situation. If we prioritise tweets that our words model infers to be Negative, then three times out of four the crowd workers will confirm this tentative labelling – showing that our model could provide a pretty useful form of triage.
It is informative to explore how our words model is making its predictions. One way to do this is to look at the posterior distribution over probWords for a label. Specifically, we are interested in words that are more common for tweets with a particular label than for tweets in general. To find such words, we can compute the ratio of the probability of each word in probLabel to the probability of the word in the dataset as a whole. Table 7.5 shows the ten words with the highest such ratio for each of the four labels.
_TrainingPercent__100-Training-TopTenWords.png)
Table 7.5For each label, the ten words with the highest probability in tweets of that label, relative to their probability in tweets in general.
The words in Table 7.5 tell a fascinating story. The Positive column is a good place to start looking – the top words here are all words of positive sentiment and ‘finally’ which suggests relief at some bad weather being over at last. But, surprisingly, words about it being ‘hot’ or ‘sunny’ do not appear in this column. In fact, ‘hot’ instead appears in the Negative column, along with many swear words. Interestingly, the Negative column also includes ‘I’ which indicates that people may tend to use more personal language when complaining about the weather (“I hate the rain”) than when being positive (“What a lovely day today”). The Neutral column has the kinds of words that a formal weather forecasting tweet might contain, such as temperatures and wind speeds – just what you might expect from a neutral tweet about the weather. Finally, the Unrelated column seems to have identified words that go with weather words in tweets that are not about the weather, such as “Snow Patrol” (a rock band) or “Snow White”.
This table helps us to understand how our words model is making predictions and also suggests the kinds of mistakes it might make. For example, an unrelated tweet about a ‘hot dog’ would likely lead our model to give an incorrect prediction of Negative. An interesting exercise is to consider how to modify Assumptions0 7.5 to address these kinds of mistakes. For example, we could consider assumptions about the probability of words co-occurring, such as ‘hot’ and ‘dog’ occurring together, conditioned on the true label of the tweet.
Wrapping up
In this chapter, we have developed a model that can learn about the biases of crowd workers by assigning them to communities of similar workers. The model can then appropriately correct for worker biases to give high accuracy labels. Where tweets are being labelled, the model can also make use of the words in the tweet to perform triage, in order to prioritise labelling the most important messages. Importantly, along the way we have learned that more flexible models are not necessarily better models!
There are a number of ways in which this model could be further improved. For example, the model could be extended to infer the difficulty of labelling each tweet, somewhat like we did for quiz questions in Chapter 2. It could also incorporate other kinds of information, such as how long it took for the annotator to produce a label. Nonetheless, the model is already competitive: Venanzi et al. [2012] used a version of this model to take part in the CrowdScale Shared Task Challenge described at the start of the chapter. Because the model can combine labels from the crowd workers with information from the words in the tweet, they were able to achieve joint first place in this challenge. What’s more, Simpson et al. [2015] compared variants of this model with a number of crowd sourcing models and found that the model with words was most accurate on two different, challenging data sets. So, at the time, the model developed in this chapter really was a competitive solution to processing crowd-sourced labels.
Even more exciting, an extension of this model by Ramchurn et al. [2015] was actually used to analyse live streams of emergency tweets received during environmental disasters in the Philippines – an excellent application of model-based machine learning!
Review of concepts introduced on this page
References
[Venanzi et al., 2012] Venanzi, M., Guiver, J., Kazai, G., and Kohli, P. (2012). Bayesian Combination of Crowd-Based Tweet Sentiment Analysis Judgments. In Crowdscale Shared Task Challenge.
[Simpson et al., 2015] Simpson, E., Venanzi, M., Reece, S., Kohli, P., Guiver, J., Roberts, S., and Jennings, N. R. (2015). Language understanding in the wild: Combining crowdsourcing and machine learning. In 24th International World Wide Web Conference (WWW 2015), pages 992–1002.
[Ramchurn et al., 2015] Ramchurn, S., Dong Huynh, T., Ikuno, Y., Flann, J., Wu, F., Moreau, L., R. Jennings, N., Fischer, J., Jiang, W., Rodden, T., Simpson, E., Reece, S., and Roberts, S. (2015). HAC-ER: A disaster response system based on human-agent collectives. Journal of Artificial Intelligence Research, 1:533–541.


 Excel
Excel CSV
CSV_TrainingPercent__100-ValidationNoLabels-ConfusionMatrixPercentage.png)