-

Want a paper copy?
You can now buy the book!
All royalties go to the Cystic Fibrosis Trust.Spotted an error? Have comments?
Let us know!Get hands on with source code for the book.
Harnessing the Crowd
In 2010 a magnitude 7.0 earthquake struck Haiti, causing massive loss of life and widespread devastation. The ensuing humanitarian aid effort was hampered by damage to communication systems, transport facilities and electrical networks. Messages from people in the affected area proved to be a vital source of information for aid workers. But these messages needed to be triaged and categorised – by volunteer workers with varying abilities, biases and attention to detail. In a future crisis, could model-based machine learning make use of such conflicting and noisy information to infer the true situation on the ground?

Around the world people are increasingly connected through their mobile phones, even in remote locations. People close to a crisis event are a vital source of information for providing disaster relief, humanitarian aid or conflict analysis. In 2008, tensions over the Kenyan presidential election erupted into outbreaks of violence, resulting in eyewitness reports sent by email and text message. A new crowd-sourcing platform was created to map these reports and determine where the violence was occurring – the platform was named Ushahidi which translates to ‘testimony’ in Swahili [Ushahidi, 2008].
The Ushahidi platform was used during the Haiti earthquake to collect and disseminate information. As reported by Norheim-Hagtun and Meier [2010], “the tool quickly became the go-to place for up-to-date crisis information, with a range of military, United Nations, and non-governmental organizations using the map as part of their needs assessment process. Preliminary feedback from these responders suggests that the project saved hundreds of lives”.
Tens of thousands of tweets, text messages, and pictures were contributed by ordinary individuals in the field to Ushahidi Haiti, and this enabled humanitarian crisis professionals to quickly get a picture of the disaster and to start to build a disaster map. Messages were translated and categorised by volunteer crowd workers, much as shown in Figure 7.1.
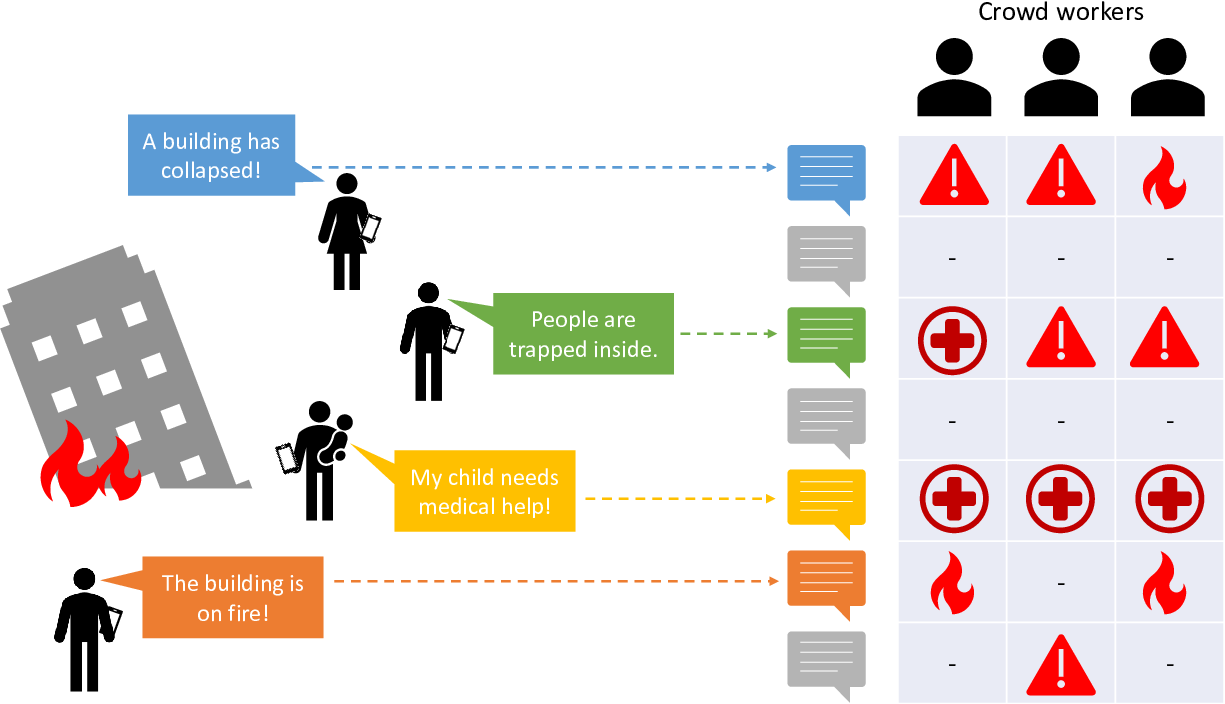
Given the quantity of messages needing categorization and the urgency of the work, it is inevitable that crowd workers sometimes categorised the same message differently. These differences may have be due to, for example, differences in judgement, insufficient training or lack of clarity in guidelines given to crowd workers. In some cases, workers deliberately misclassified messages “because of a concern that messages not associated with a specific classified need might be ignored” [Morrow et al., 2011]. The net effect was that different workers exhibited different biases is how they labelled messages.
One of the recommendations coming out of the use of Ushahidi in Haiti was to “Implement more rigorous quality assurance techniques to monitor accuracy of classifications in near real-time”. In this chapter, we will look at how to automatically improve classifications by modelling worker biases, using both the crowd worker assessments and the messages themselves. The goal will be to work out the best category label for each message, taking into account the abilities and biases of individual crowd workers. The hope is that any increase in categorization accuracy that we can achieve could lead to lives being saved in the next humanitarian crisis.
The model developed in this chapter is based on the models described in Venanzi et al. [2012] and Venanzi et al. [2014]. You can also refer to the source code for the chapter [Diethe et al., 2019].
[Ushahidi, 2008] Ushahidi (2008). http://www.ushahidi.com/.
[Norheim-Hagtun and Meier, 2010] Norheim-Hagtun, I. and Meier, P. (2010). Crowdsourcing for Crisis Mapping in Haiti. Innovations: Technology, Governance, Globalization, 5(4):81–89.
[Morrow et al., 2011] Morrow, N., Mock, N., Papendieck, A., and Kocmich, N. (2011). Independent Evaluation of the Ushahidi Haiti Project.
[Venanzi et al., 2012] Venanzi, M., Guiver, J., Kazai, G., and Kohli, P. (2012). Bayesian Combination of Crowd-Based Tweet Sentiment Analysis Judgments. In Crowdscale Shared Task Challenge.
[Venanzi et al., 2014] Venanzi, M., Guiver, J., Kazai, G., Kohli, P., and Shokouhi, M. (2014). Community-based Bayesian Aggregation Models for Crowdsourcing. In Proceedings of the 23rd International Conference on World Wide Web, WWW ’14, pages 155–164, New York, NY, USA. ACM.
[Diethe et al., 2019] Diethe, T., Guiver, J., Zaykov, Y., Kats, D., Novikov, A., and Winn, J. (2019). Model-Based Machine Learning book, accompanying source code. https://github.com/dotnet/mbmlbook.