-

Want a paper copy?
You can now buy the book!
All royalties go to the Cystic Fibrosis Trust.Spotted an error? Have comments?
Let us know!Get hands on with source code for the book.
Interlude: the machine learning life cycle
In tackling our murder mystery back in Chapter 1, we first gathered evidence from the crime scene and then used our own knowledge to construct a probabilistic model of the murder. We incorporated the crime scene evidence into the model, in the form of observed variables, and performed inference to answer the query of interest: what is the probability of each suspect being the murderer? We then assessed whether the results of inference were good enough – that is, was the probability high enough to consider the murder solved? When it was not, we then gathered additional data, extended the model, re-ran inference and finally reached our target probability.
In assessing skills of job candidates in Chapter 2, we gathered data from people taking a real test and visualised this data. We then built a model based on our knowledge of how people take tests. We ran inference and assessed that the results were not good enough. We diagnosed the problem, extended the model and then evaluated both the original and the extended models to quantify the improvement and check that the improved model met our success criteria.
We can generalise from these two examples to define the steps needed for any model-based machine learning application:
- Gather data for training and evaluating the model.
- Gather knowledge to help make appropriate modelling assumptions.
- Visualise the data to understand it better, check for data issues and gain insight into useful modelling assumptions.
- Construct a model which captures knowledge about the problem domain, consistent with your understanding of the data.
- Perform inference to make predictions over the variables of interest using the data to fix the values of other variables.
- Evaluate results using some evaluation metric, to see if they meet the success criteria for the target application.
In the (usual) case that the system does not meet the success criteria the first time around, there are then two additional steps needed:
- Diagnose issues which are reducing prediction accuracy. Visualisation is a powerful tool for bringing to light problems with data, models or inference algorithms. Inference issues can also be diagnosed using synthetic data sampled from the model (as we saw in Chapter 2). At this stage, is may also be necessary to diagnose performance issues if the inference algorithm is taking too long to complete.
- Refine the system – this could mean refining the data, model, visualisations, inference or evaluation.
These two stages need to be repeated until the system is performing at a level necessary for the intended application. Model-based machine learning can make this repeated refinement process much quicker when using automatic inference software, since it is easy to extend or modify a model and inference can then be immediately applied to the modified model. This allows for rapid exploration of a number of models each of which would be very slow to code up by hand.
The stages of this machine learning life cycle can be illustrated in a flow chart:
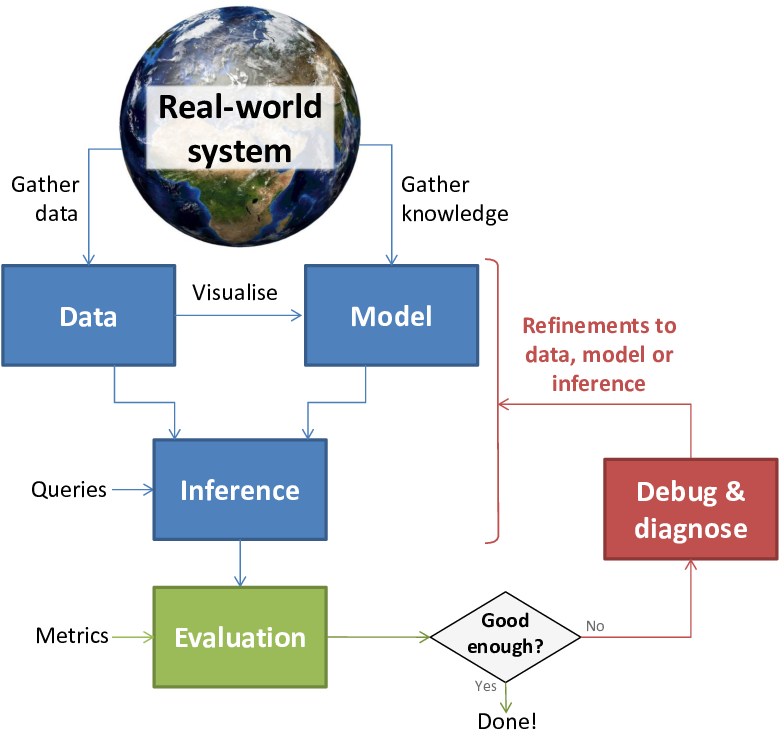
As we move on to our next case study, keep this life cycle flowchart in mind – it will continue to be useful as a template for solving machine learning problems.