-

Want a paper copy?
You can now buy the book!
All royalties go to the Cystic Fibrosis Trust.Spotted an error? Have comments?
Let us know!Get hands on with source code for the book.
8.1 Latent Dirichlet Allocation

LDA is a model of multiple documents.
Latent Dirichlet Allocation (LDA) is a model of the words in a set of documents or of other kinds of data with similar structure, such as sets of genetic sequences or images. LDA is a kind of topic model – a model which aims to discover the topics being written about in a set of documents, and also annotate each piece of text with the topics mentioned in it. This model was first developed by Pritchard et al. [2000] in the context of population genetics, and then independently rediscovered by Blei et al. [2003] who named it LDA. The relative simplicity of the model, along with its applicability to a broad range of data types, has made it one of the most popular and widely used machine learning models, particularly for analysing textual data.
In previous chapters, we have built up a factor graph by making a series of assumptions about the problem domain. In this chapter, we will reverse this process: we will start with a factor graph and analyse it to understand the assumptions that it is making – much as we might do for any published model that we would like to understand. Following this process, we need the factor graph for LDA so that we can analyze it. This factor graph can be found in Blei et al. [2003], a version of which is shown in Figure 8.1.
|
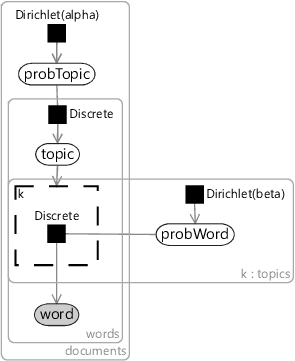
To analyse this factor graph, we can start by exploring what each variable is – what type it has and what the variable means in the problem domain. It is usually easiest to start with observed variables since they correspond to the data being processed. In this model, there is one observed variable: word. This word variable lies in a plate over words inside a plate over document, so the observed data is all the words in some set of documents. The type of word is discrete (a.k.a. categorical) which here means that its value identifies a particular word – we can think of this as the index of the word in a particular vocabulary of words.
From the factor graph, we can see that probWord is a probability distribution over the words in the vocabulary. We can also see that probWord lies inside a plate over topics – so there is one such distribution for each topic. Since this is the only topic-specific variable, it shows that a topic is entirely characterised by its distribution over words. The gate structure in the middle shows that the topic variable switches between these topic-specific distributions. Because the topic variable lies inside plates over words and documents, we can see that this topic switching happens for each word individually. In other words, each word has its own topic label.
Finally, probTopic is a probability distribution over topics. It lives inside the plate over documents, showing that each document has its own distribution over the topics in that document.
Exploring the assumptions in LDA
We’ve described the factor graph of Figure 8.1 at a factual level – now let’s see how to read off the assumptions being made in this graph. Again, let’s start with the observed variable word. We can see from the graph that the only parent of word that is word- or document-specific is the topic variable. So the model is assuming that the topic is the only characteristic of the word or document that affects the choice of word used. More precisely, the assumption is:
- The probability of writing a particular word depends only on the topic being written about.
Our goal is to understand what the LDA model does and where it can be applied. So, let’s consider situations where this assumption would and would not hold. We could start by considering what, other than the topic, might affect word choice – for example:
- The author – two different people are likely to use different words when talking about the same topic;
- The kind of document – the choice of word is also likely to vary depending on the kind of document being written. For example, a technical paper on a topic might use different words to a news article on the same topic – and a tweet about the topic would likely use yet different words again.
- When the document was written – use of words changes slowly over time. Two documents about the same topic written many years apart would be very likely to have differing distributions of words, even if written by the same person.
- The language – writing about the same topic in different languages would definitely lead to very different words being used!
All of these variables could cause a change to the distribution of words unrelated to the topic being written about. If we want our inferred topic variable to actually correspond to the topic of the document, then we would need to keep all such variables fixed. For example, we would want to run LDA on documents of the same kind, in the same language, written by the same author at around the same time. The first two of these are usually quite easy to achieve. There are many collections of documents available where all documents are the same kind and written in the same language – for example, news articles. However, such documents collections are not usually written by a single author and may have been written over many years. The risk of using LDA in such cases is that the inferred topics might start to depend on the author or time as well as the actual topic (or on some combination of these), rather than on the topic alone.
Let’s explore some more assumptions – looking at the factor graph, we can see that the topic and word variables sit insides a plate over the words. This means that the process for generating the topic for each word, and for generating the word itself, is identical for every word in the document. To put this another way, you could re-order the words in a document and the topics inferred for each word would remain exactly the same. There are two underlying assumptions here:
- Changing the order of words in a document has no affect on the topic being talked about.
- The topics of two words are just as likely to be the same if the words are adjacent, as if they are far away.
Assumptions0 8.2 is a very poor assumption as a model of text. If you re-order the words in a document then it will likely make very little sense, and should definitely not be considered equivalent to the original document! Yet, for the purpose of identifying topics, re-ordering may not be so bad – the relevant question is ‘do we expect to be able to tell the topic of a word, even if we ignore the surrounding words?’. In many cases, the word alone may be enough to clearly define the topic. An exception would be for phrases where we several words in order have a meaning that the individual words lack. Back in section 7.5, we found our model trying to distinguish between tweets about “snow” and about “snow patrol”. Distinguishing between these two topics is going to be very sensitive to word order! LDA would struggle to provide correct topic labels in such cases.
Assumptions0 8.3 may also be a poor assumption in practice, if the goal is to have words reliably labelled with topics. In most documents, we may expect entire sentences, or even entire paragraphs, to be about the same topic. But LDA is unlikely to give the same topic label to all the words in a sentence or paragraph, since it is making independent choices for each word. For example, the phrase “track and field” is likely related to the topic of athletics, but the middle word “and” by itself is not. Even if “track” and “field” were correctly labelled, it is most likely that “and” would be inferred to have an entirely different topic label. In practice, such neutral words like “and” often end up assigned to a general-purpose topic, for words that are used in many contexts. If the goal is to infer the topics of the document, rather than the topic of individual words or sentences, then LDA can work well despite this assumption – the overall distribution of topic labels can be usefully accurate even if the labels for individual words are not.
Moving up to the top of the factor graph, we can consider what assumptions are being made about the topics overall. One assumption is:
The size of the topic plate is fixed and so we are assuming that this number of topics is known. In practice, LDA is often used in an unsupervised way, to discover topics in a set of documents. In such an application, there is no reason to believe that the number of topics would be known. This assumption can be sidestepped to an extent by exploring many different values of and seeing which is best for the intended application.

A document is unlikely to talk about both patisserie and politics.
A more concerning assumption arises because of the Dirichlet prior on probTopic:
On the surface, Assumptions0 8.5 is a very odd assumption. There are topics which are very unlikely to be addressed in the same document (such as political commentary and patisserie recipes) and others which are much more likely to be mentioned together (such as political commentary and economic analysis). The symmetry between topics in the Dirichlet prior means the LDA model treats both equally. What’s more, with the parameter alpha fixed, the model cannot even learn which topics are more or less common! As with many questionable choices of prior distribution, the hope here is that the data will overwhelm the prior. In other words, it doesn’t matter if the model assumes that all topics are equally likely to co-occur, since the observed words will provide plenty of evidence as to which topics are being talked about. For reasonably long documents, it is likely that the prior would indeed be overwhelmed in this way. For shorter documents, such as tweets, having a more carefully designed prior would likely have a significant benefit.
In summary, our analysis of the assumptions suggest that LDA is likely to work well for similar kinds of documents, written in the same language and style, where the documents are not too short and not too dependent on multi-word phrases. Such conditions apply moderately well to many common data sets of documents, which no doubt explains why LDA is a popular model in many such cases.
Extensions to LDA
As we have seen, the LDA model makes a number of assumptions which limit either its applicability or its accuracy. Happily, the model can be extended in a variety of ways to overcome these assumptions. For example, Assumptions0 8.5, that any pair of topics are equally likely to be talked about in the same document, arises from the choice of a Dirichlet distribution over probTopic. We can change this assumption by changing the form of the prior. In the Correlated Topic Model [Blei and Lafferty, 2006], the authors replace the Dirichlet prior with a logistic-normal prior capable of representing correlations between topics. The resulting model then gives much higher log-likelihood scores than LDA when the number of topics is large, where learning the correlations between topics is going to be particularly benefitical. The learned correlations between topics also means that topics connect to each other, forming a graph. Such a topic graph identifies related topics, providing a useful way to browse a set of topics, along with their associated documents.
Other extensions to LDA have been made when applying it to different kinds of data. The computer vision community explored making use of LDA by defining ‘documents’ to be images or regions of images and ‘words’ to be patches of the image. Various extensions were then developed to tailor the LDA model to make it more suitable to imaging applicatons. For example, the Spatial Latent Dirichlet Allocation model [Wang and Grimson, 2007] attempted to divide an image into regions (documents) containing patches (words) of similar appearance. This model is a particularly interesting use of LDA since it assumes that the allocation of words to documents is unknown, and so needs to be inferred at the same as time as the topic appearances and distributions over topics.
Over the years, there have been a variety of other extensions to LDA, each changing some part of the original model so as to replace or modify one of the assumptions being made. The result is an excellent demonstration of the modularity of probabilistic models – such models really can have pieces added, removed or replaced to meet the requirements of the problem domain where they are being applied.
Latent Dirichlet AllocationA model of the words in a set of documents which assumes each word has an associated topic and that each document has an associated distribution over topics. In typical use, the topics and their distributions are inferred unsupervised given a set of documents. Latent Dirichlet Allocation can also be applied to other kinds of data with similar structure, such as sets of genetic sequences or images.
topic modelA model which aims to discover topics in text (or other kinds of data) and also annotate text with the topics being written about.
[Pritchard et al., 2000] Pritchard, J. K., Stephens, M., and Donnelly, P. (2000). Inference of population structure using multilocus genotype data. Genetics, 155(2):945–959.
[Blei et al., 2003] Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3(4–5):993–1022.
[Blei and Lafferty, 2006]
[Wang and Grimson, 2007] Wang, X. and Grimson, E. (2007). Spatial Latent Dirichlet Allocation. In Proceedings of the 20th International Conference on Neural Information Processing Systems}, NIPS’07, pages 1577–1584.