-

Want a paper copy?
You can now buy the book!
All royalties go to the Cystic Fibrosis Trust.Spotted an error? Have comments?
Let us know!Get hands on with source code for the book.
4.1 Collecting and managing email data
For the purposes of writing this chapter, we developed a tool for collecting all of a person’s email received in a given time period. We then used the tool to collect emails from 10 volunteers who kindly agreed to share their email data – in an anonymised form, as we shall discuss shortly. This was quite a time consuming process and so we need to plan carefully about how we are going to use this precious email data. For example, we need to decide which data we will use to train on and which data we will use to evaluate the system’s accuracy. It is very important that the data used for training is not used for evaluation. If training data is used for evaluation it can give misleadingly high accuracy results – because it is much easier to make a prediction for an email when you’ve already been told the correct answer! To avoid this, we need to divide our data into different data sets:
- A training set which we will use to train the model;
- A separate test set which we will use to assess the prediction accuracy for each user and so indicate what we might expect to achieve for real users.
If you were to evaluate a trained model on its training set, it will tend to give higher accuracy results than on a test set. The amount that the accuracy is higher on the training set indicates how much the model has learned that is specific to the particular data in the training set, rather than to that type of data in general. We say that a model is overfitting to the training data, if its accuracy is significantly higher on the training set than on a test set.
If we were only planning to evaluate our system once, these two data sets would be sufficient. However, we expect to make repeated changes to our system, and to evaluate each change to see if it improves prediction accuracy. If we were to evaluate on the test set many times, making only the changes that improve the test set accuracy, we would run the risk of overfitting to the test set. This is because the process of repeatedly making changes that increase the test set accuracy could be picking up on patterns that are specific to the test and training set combined but not to general data of the same type. This overfitting would mean that the accuracy reported on the test set would no longer be representative of what we might expect for real users. To avoid overfitting, we will instead divide our data into three, giving a third data set:
- A validation set which we will use to evaluate prediction accuracy during the process of developing the system.
We can evaluate on the validation set as many times as we like to make decisions about which changes to make to our system. Once we have a final system, we will then evaluate once on the test set. If it turns out that the model has been overfitting to the validation set, then the accuracy results on the test set will be lower, indicating that the real user accuracy will be lower than we might have expected from the validation set accuracy numbers.
If the test set accuracy is not yet sufficient, it would then be necessary to make further changes to the system. These can again be assessed on the validation set. At some point, a new candidate system would be ready for test set evaluation. Strictly speaking, a fresh test set should be used at this point. In practice, it is usually okay to evaluate on a test set a small number of times, bearing in mind that the numbers may be slightly optimistic. However, if used too much, a test set can become useless due to the possibility of overfitting, at which point it would then be necessary to gather a fresh test set.
For the email data that we collected, we can divide each user’s emails into training, validation and test sets. Since the goal is to make predictions on email arriving in the user’s inbox, we exclude emails in the user’s Sent Mail and Junk folders from these data sets, since such emails did not arrive in the inbox. We also exclude emails which were automatically moved by a rule, since such emails also did not appear in the inbox. Table 4.1 gives the sizes of the training, validation and test sets for each user, after removing such non-inbox emails.
 Excel
Excel CSV
CSV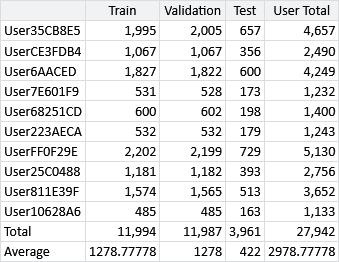
Learning from confidential data
Table 4.1 highlights another challenge when working with email data – it is highly personal and private data! Email data is an example of personally identifiable information (PII), which is information that could be used to identify or learn about a particular person. For an email, personally identifiable information includes the names and email addresses on the email along with the actual words of the subjects and email bodies. Knowing which senders a particular user ignores or replies to, for example, would be very sensitive data. In any system that uses PII, it is essential to ensure that such data is kept confidential.

In a machine learning system, this need for confidentiality appears to conflict with the need to understand the data deeply, monitor the performance of the system, find bugs and make improvements. The main technique used to resolve this conflict is some kind of anonymisation, where the data is transformed to remove any PII whilst retaining the underlying patterns that the machine learning system can learn from. For example, names and email addresses can be anonymised by replacing them with arbitrary codes. For this project, we anonymise all user identities using an alphanumeric hash code like ‘User35CB8E5’, as shown in Table 4.1. This type of anonymisation removes PII (or at least makes it extremely difficult to identify the user involved) but preserves information relevant to making predictions, such as how often the user replies to each person.
In some cases, anonymisation is hard to achieve. For example, if we anonymised the subject and body on a word-by-word basis, this anonymisation could potentially be reversed using a word frequency dictionary. For this reason, we have removed the email bodies and subject lines from the data used for this chapter, so that we can make it available for download while protecting the confidentiality of our volunteers. We will retain the lengths of the subject lines and body text, since they are useful for making predictions but do not break confidentiality. If you wish to experiment with a more complete email data set, there are a few such available, an example of which is the Enron email dataset [The CALO Project, 2004]. Notice that, even for this public Enron data set, some emails were deleted “as part of a redaction effort due to requests from affected employees”, demonstrating again the sensitive nature of email data! For cases like these where anonymisation cannot easily be achieved, there is an exciting new method under development called homomorphic encryption which makes it possible to do machine learning on encrypted data without decrypting the data first. This approach is at the research stage only, so is not yet ready for use in a real application (but read more in Panel 4.1 if you are curious).
Using our anonymised and pruned data set means that we can inspect, refine, or debug any part of the system without seeing any confidential information. In some cases, this anonymisation can make it hard to understand the system’s behaviour or to debug problems. It is therefore useful to have a small non-anonymised data set to work with in such cases. For this chapter we used a selection of our own emails for this purpose. For a deployed system, you can also ask real users to voluntarily supply a very limited amount of what would normally be confidential information, such as a specific email. It is important to allow the user to review exactly what information is being shared and ensure the information is only used for the purpose of debugging the issue they are reporting, for example, an incorrect prediction.
Now that we have training and validation data sets in a suitably anonymised form, we are ready to start developing our model.
training setThe part of the collected data which will be used for model training.
test setThe part of the collected data which will be used to assess a trained model’s accuracy. This evaluation should be performed infrequently, ideally only once, to avoid overfitting to the test set.
overfittingThe situation where a trained model has learned too much about patterns in the data that are specific to the training set, rather than patterns relating to general data of the same form. If a model is overfitting, its prediction accuracy on data sets other than the training set is reduced.
validation setThe part of the collected data which will be used to assess a trained model’s accuracy as the model is being developed. Typically the validation set is used repeatedly to decide whether or not to make changes to the model. This runs the risk of overfitting to the validation set, which is why it is important also to have a separate test set.
personally identifiable informationAny information about a person which could be used to identify who they are or to learn confidential information about them.
anonymisationA process where data is transformed to remove any personally identifiable information, whilst retaining enough information to be useful. For example, email addresses can be anonymised by replacing them by a randomly generated string, such that the same address is always replaced by the same string. This allows patterns of email use to be identified without associating those patterns with any given sender or recipient.
[The CALO Project, 2004] The CALO Project (2004). Enron email data set. http://www.cs.cmu.edu/ enron.
[Graepel et al., 2013] Graepel, T., Lauter, K., and Naehrig, M. (2013). Ml confidential: Machine learning on encrypted data. In Kwon, T., Lee, M.-K., and Kwon, D., editors, Information Security and Cryptology - ICISC 2012, volume 7839 of Lecture Notes in Computer Science, pages 1–21. Springer Berlin Heidelberg.